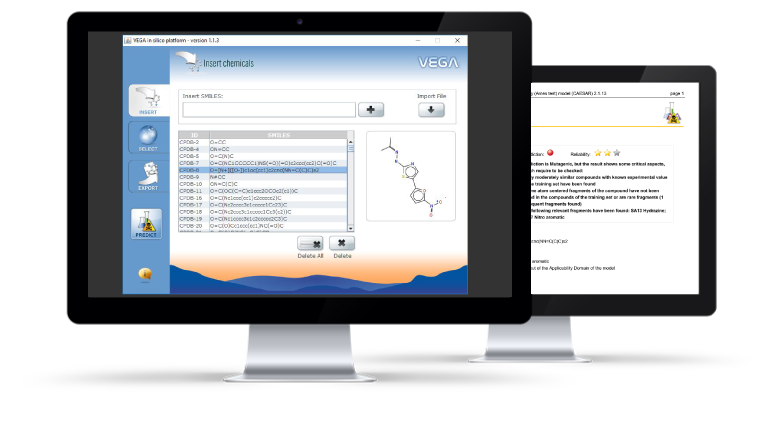
Here you can download in Silico models (QSAR and read across) for specific properties, or programs to build up your own model
- Description
RAXpy: a read-across tool based on structural, biological and metabolic similarities.
Filters based on the presence of maximum common substructures and common functional groups between the target and the source dataset can be applied to narrow the chemical space for the analogue(s) search.
- Last Release
- December 14, 2021
- Description
ToxEraser Cosmetics.
The software, freely available, has been designed taking into account the level of safety, the functional uses and a similarity algorithm as cornerstones of the architecture.
- Last Release
- December 14, 2021
- Description
VERMEER FCM.
The software, freely available, has been designed in line with the regulatory framework for plastics FCM (Regulation EU No 10/2011)
- Last Release
- January 21, 2022
- Description
The available dataset of each model included in VEGA is listed, grouped within the six VEGA thematic area.
- Last Release
- December 25, 2020
- Description
The Nuclear Receptor-Mediated Endocrine Activity model.
The models have been developed by the group of Prof. Wei Shi, University of Nanjing.
- Last Release
- December 8, 2019
- Description
A collection of tools to build up QSAR models, and integrate them.
The models have been developed by the Jadavpur University, in the team coordinated by Prof Kunal Roy.
- Last Release
- October 2, 2019
- Description
JANUS expands the prioritization for PBT developed previously by the project PROMETHEUS.
The German Federal Ministry for the Environment, Nature Conservation, Building and Nuclear Safety recently funded a new project, called JANUS (FKZ 3716 65 4140), to prioritize and screen substances, considering PBT (persistent, bioaccumulative and toxic), CMR (carcinogenic, mutagenic and reprotoxic) sustances, as well as chemicals supposed to be endocrine disruptors. A consortium of three partners, Istituto di Ricerche Farmacologiche Mario Negri, Kode and KnowledgeMiner, will develop a platform within the JANUS project. JANUS further expands the previous prioritization project for PBT, called PROMETHEUS
- Last Release
- January 31, 2017
- Description
The Prometheus application provides an overall PBT (persistence, bio-concentration, toxicity) assessment based on QSAR modelling, combined in a final score useful for ranking compounds.
- Last Release
- February 28, 2017
- Description
SARpy allows you to develop a model to classify chemicals according to a given property, such as carcinogenicity or fish toxicity.
SARpy breaks the chemical structures of the compounds in the training set into fragments of a desired size, and it identifies fragments related to the target property. It then also shows the fragments related to the effect. Inhibiting conditions are identified which prevent the appearance of the effect, even in presence of the active fragment. The system uses SMILES in the canonical form. It allows choice in building more conservative or more accurate models.
- Last Release
- January 31, 2017
- Description
ToxDelta nicely complements ToxRead. ToxDelta keeps into account the differences, and thus the dissimilarity features.
ToxDelta is a program which identifies the differences between two substances, and if these differences are related an increase or decrease of the effect. It nicely complements ToxRead. While ToxRead identifies the similar compounds and the common structural alerts between the target and similar compound, ToxDelta keeps into account the differences, and thus the dissimilarity features.
A preliminary BETA version is available for download.
- Last Release
- January 31, 2017
